ABAP
秋招
广度优先
高数
JWT
opencv
DOM型XSS
信号维度
rpc
HuggingFace
activity7
数据压缩
EMC
firefox
线段树
可视化
3D建模
运动场地预约
均线策略
数据中台
数据预处理
2024/4/11 18:59:52CSI指纹预处理(中值、均值、Hampel、维纳滤波、状态统计滤波器)
目录
前言
1、箱线法
2、中值滤波器
3、均值滤波器
4、Hampel滤波器
5、维纳滤波
6、状态统计滤波器 前言
因为设备、温度和实验室物品摆设等因素的影响,未经处理的CSI数据不能直接使用,需要对数据进行异常值处理以保证数据的稳定性,…
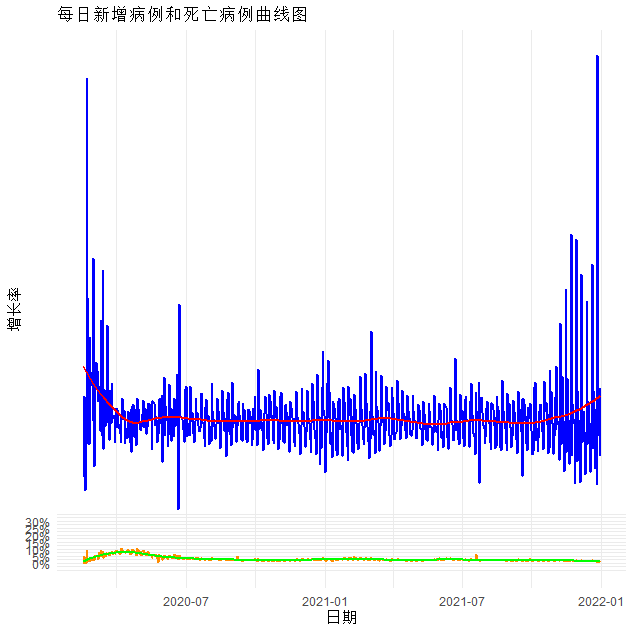
如何用R语言分析COVID-19相关数据
一、概述
COVID-19是当前全球面临的一项重大挑战。 本文将介绍如何使用R语言分析COVID-19相关数据,探索其感染率、死亡率和人口特征的相关性,以及使用统计建模方法预测COVID-19的死亡率。
二、数据导入与筛选
COVID-19 Data Repository by the Center…
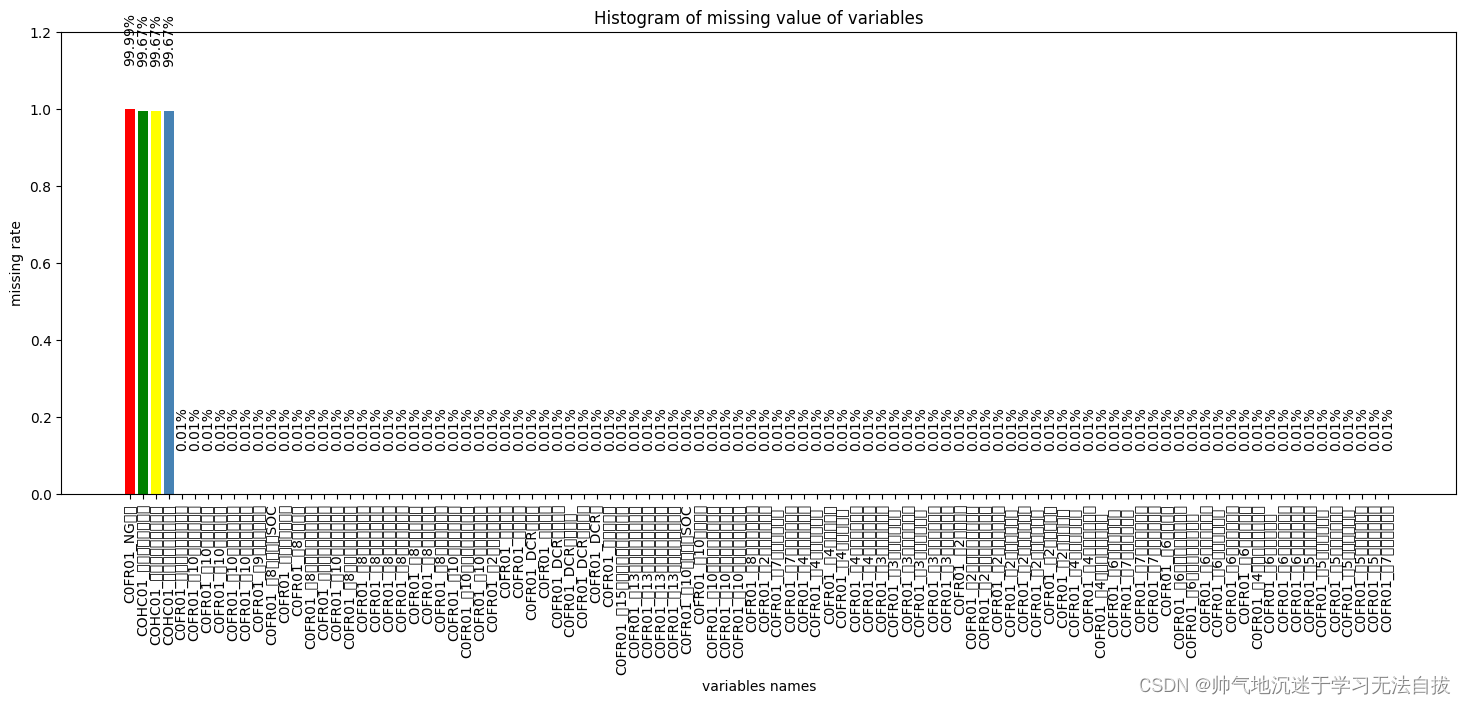
大数据HCIE成神之路之数据预处理(1)——缺失值处理
缺失值处理 1.1 删除1.1.1 实验任务1.1.1.1 实验背景1.1.1.2 实验目标1.1.1.3 实验数据解析 1.1.2 实验思路1.1.3 实验操作步骤1.1.4 结果验证 1.2 填充1.2.1 实验任务1.2.1.1 实验背景1.2.1.2 实验目标1.2.1.3 实验数据解析 1.2.2 实验思路1.2.3 实验操作步骤1.2.4 结果验证 1…

数据挖掘算法原理与实践:数据预处理
目录
第1关:标准化
相关知识
为什么要进行标准化
Z-score 标准化
Min-max 标准化
MaxAbs 标准化
代码文件
第2关:非线性转换
相关知识
为什么要非线性转换
映射到均匀分布
映射到高斯分布
Yeo-Johnson 映射
Box-Cox 映射
代码文件
第3关…

100 Days Of ML Code:Day1-Data Preprocessing(数据预处理)
100天机器学习挑战汇总文章链接在这儿。 Data Preprocessing -- Getting Started with Machine Learning
第1天学习的内容主要是数据预处理。主要包括:
目录
Step 1:导入库
Step 2:导入数据集
Step 3:处理缺失数据
Step 4&a…

Pytorch中的nn.AdaptiveAvgPool2d(output_size)简单介绍
文章目录1 什么是池化?(Pooling)2 adaptivePooling和GeneralPooling3 代码调用1 什么是池化?(Pooling)
Pooling,池化层,又称下采样、汇聚层,是从样本中再选样本的过程。…

ch02-PyTorch数据预处理
ch02-PyTorch数据预处理0.引言1.数据读取机制 Dataloader 与 Dataset1.1.纸币二分类1.2.DataSet与DataLoader1.2.1.torch.utils.data.DataLoader:构建可迭代的数据装载器1.2.2.torch.utils.data.Dataset:Dataset抽象类1.2.3.以人民币分类为例2.数据预处理…

2.预备知识-3GPT版
#pic_center R 1 R_1 R1 R 2 R^2 R2 目录 知识框架No.1 数据操作数据预处理一、N维数组样例二、创建数组三、访问元素四、数据操作D2L注意点五、数据预处理D2L注意点六、QA No.2 线性代数一、标量二、向量1、基本操作2、空间表示3、乘法 三、矩阵1、基本操作2、乘法3、空间表…

数据预处理中的归一化和标准化
数据预处理中的归一化和标准化
由于近来在做kaggle的泰坦尼克号入门比赛,特此记录日常发现的疑惑。
一, 数据标准化和归一化的原因
维基百科给出的解释: 1)归一化后加快了梯度下降求最优解的速度; 2)归一…
归一化、中心化、标准化、正则化的区别
温馨提示:本文由ChatGPT生成 在数据处理和特征工程中,归一化、中心化、标准化和正则化是常用的数据转换技术。虽然它们有一些相似之处,但在具体操作和效果上存在一些区别。下面是它们的解释和区别:
归一化(Normalizat…

降维:特征选择与特征提取
对于降维,我看可以简单理解为减少数据的维度,说白了就是减少变量个数。文末的视频墙裂推荐观看一下。 特征选择: 不改变变量的含义,仅仅只是做出筛选,留下对目标影响较大的变量。
Backward Elimination(反…
sklearn.preprocessing数据标准化实现流程
python中对于训练集一般需要标准化,即将原数据的均值变为0,方差变为1
有两种方式:
from sklearn import preprocessing
第一种:使用scale模块直接计算标准化,将标准化的array放在x_scale中,同时可以查看均值和标准差&a…

数据预处理方式(去均值、归一化、PCA降维)
转载链接 https://blog.csdn.net/maqunfi/article/details/82252480 一.去均值 1.各维度都减对应维度的均值,使得输入数据各个维度都中心化为0,进行去均值的原因是因为如果不去均值的话会容易拟合。 这是因为如果在神经网络中,特征值x比较大…
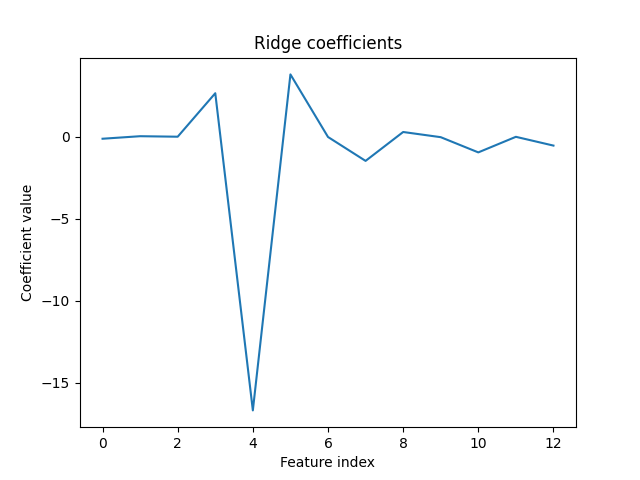
基于Python的特征工程:数据预处理(一)
一、概述
特征工程是机器学习工作流程中不可或缺的一环,它将原始数据转化为模型可理解的形式。数据和特征的质量决定了机器学习的上限,而模型和算法则是逼近这个上限的手段。因此,特征工程的重要性不言而喻。其主要工作涉及特征的采集、预处…
计算机视觉中图片数据的预处理
本文重点
图片数据是计算机视觉处理的核心,一般的图片数据并不能直接放到神经网络中,而是应该使用一些数据与处理的方式来解决,这个操作我们称为图片数据的预处理。
图像缩放
图像缩放是指将图像的尺寸调整为所需的大小。在AI中,图像缩放通常用于将图像调整为模型所需的…
Pandas中你一定要掌握的时间序列相关高级功能
💡 作者:韩信子ShowMeAI 📘 数据分析实战系列:https://www.showmeai.tech/tutorials/40 📘 本文地址:https://www.showmeai.tech/article-detail/389 📢 声明:版权所有,转…
CSI指纹预处理(中值、均值、Hampel、小波滤波)
目录
1、前言
2、中值滤波器
3、均值滤波器
4、Hampel滤波器
5、小波变换滤波器
1、前言
因为设备、温度和实验室物品摆设等因素的影响,未经处理的CSI数据不能直接使用,需要对数据进行异常值处理以保证数据的稳定性,同时减少环境中人的…
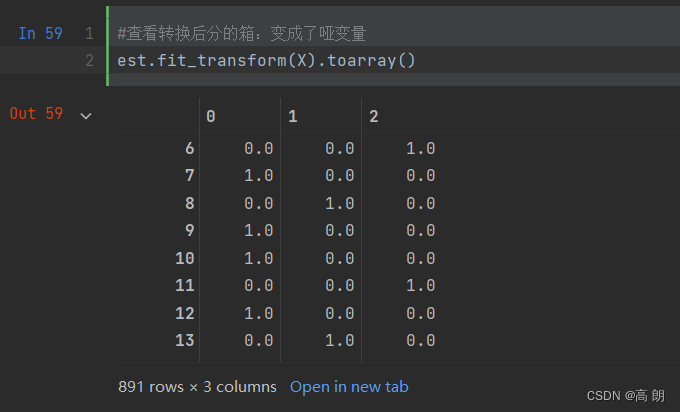
【机器学习】sklearn对数据预处理
文章目录 数据处理步骤观察数据数据无量纲化缺失值处理处理分类型特征处理连续型特征 数据处理步骤
数据无量纲化缺失值处理处理分类型特征:编码与哑变量处理连续型特征:二值化与分段 观察数据
通过pandas读取数据,通过head和info方法大致查…

【C++算法模板】预处理算法:一维前缀和、二维前缀和总结,详解带例题
文章目录 0)概述1)一维前缀和2)二维前缀和 0)概述
因为前缀和这个板子的推导比较简单,因此本博客重点在于知识点归纳而不在于证明
1)一维前缀和
一维数组的前缀和计算公式: s [ i ] ∑ i 1…
![[自然语言处理|NLP] 文本分类与情感分析,数据预处理流程,包括了同义词替换和拼写纠正,以及使用NLTK库和TextBlob库进行标记化和情感分析(附代码)](https://img-blog.csdnimg.cn/direct/48f1bd6566364ab88ba1f5fb9cb9b583.png)
[自然语言处理|NLP] 文本分类与情感分析,数据预处理流程,包括了同义词替换和拼写纠正,以及使用NLTK库和TextBlob库进行标记化和情感分析(附代码)
[自然语言处理|NLP] 文本分类与情感分析,数据预处理流程,包括了同义词替换和拼写纠正,以及使用NLTK库和TextBlob库进行标记化和情感分析(附代码)。
自然语言处理(Natural Language Processing,简称NLP)是人工智能领域的一个重要分支,涉及了处理和理解人类语言的技术…
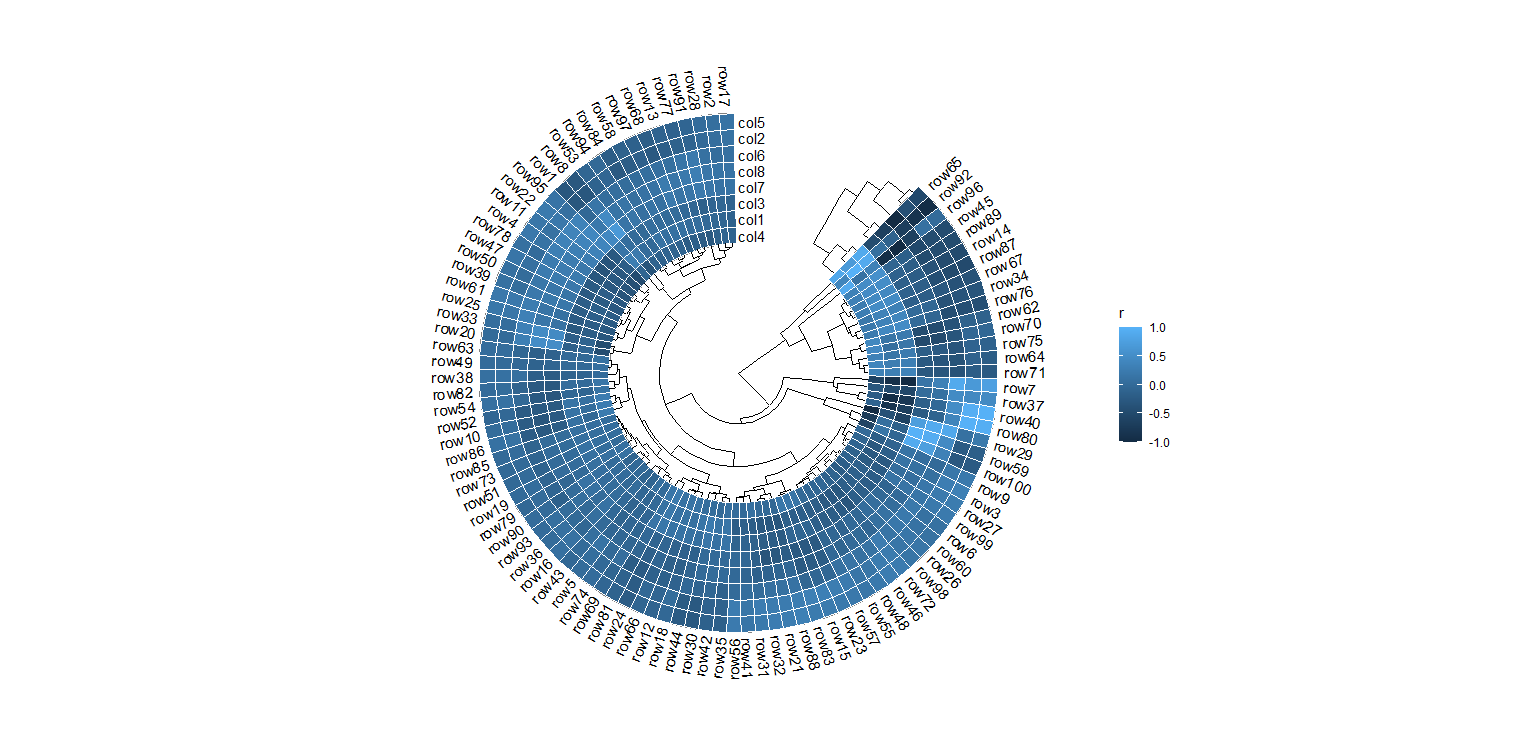
无热图不组学!高阶文献热图R语言绘制小专场拿捏
一、概述
近在阅读近五年的一区高分的机器学习文献,其中有一种图出现频率特别高——热图。《Machine Learning and the Future of Cardiovascular Care: JACC State-of-the-Art Review》 《Comparison of Machine Learning Methods for Predicting Outcomes After…
数据挖掘——数据预处理
一、背景 原始数据存在的几个问题:不一致;重复;含噪声;维度高。 1.1 数据挖掘中使用的数据的原则
尽可能赋予属性名和属性值明确的含义;去除惟一属性;去除重复性;合理选择关联字段。
1.2 常见的…

数据预处理-分箱(Binning)和 WOE编码
数据预处理-分箱(Binning)和 WOE编码
1. 分箱
1.1 理论
1.1.1 定义 分箱就是将连续的特征离散化,以某种方式将特征值映射到几个箱(bin)中。
1.1.2 为什么要进行分箱?
引入非线性变换,增强模型性能。因为原始值和目…
数据处理:归一化与标准化
归一化与标准化 归一化和标准化是数据预处理时常用的方法,它们都可以将数据映射到特定的区间内,但是具体的实现方式和应用场景有所不同。 1 归一化与标准化的相同点
都能够处理特征值之间的差异性,避免特征值之间的度量不一致或者差异过大都…
Sklearn数据预处理
sklearn.preprocessing 包提供了几个常见的实用功能和变换器类型,用来将原始特征向量更改为更适合机器学习模型的形式。
一般来说,机器学习算法受益于数据集的标准化。如果数据集中存在一些离群值,那么稳定的缩放或转换更合适。不同缩放、转…

踏上机器学习之路:探索数据科学的奥秘与魅力
✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨ 🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。 我是Srlua小谢,在这里我会分享我的知识和经验。&am…

python电商数据预处理
电商数据预处理
今天对电商数据进行了预处理,主要处理了 1. 提取2019年的订单数据 2. 处理业务流程不符的数据(支付时间早于下单时间、支付时长超过30分钟、订单金额小于0、支付金额小于0) 3. 处理渠道为空的数据(补充众数&#…
掌握Pandas数据筛选方法与高级应用全解析【第70篇—python:数据筛选】
文章目录 掌握Pandas:数据筛选方法与高级应用全解析1. between方法2. isin方法3. loc方法4. iloc方法5. 查询复杂条件的结合应用6. 避免inplace参数7. 利用Lambda函数进行自定义筛选8. 处理缺失值9. 多条件排序10. 数据统计与分组 总结: 掌握Pandas&…

基于Python实现地标景点识别
目录 前言简介地标景点识别的背景 地标景点识别的原理卷积神经网络(CNN)的基本原理地标景点识别的工作流程 使用Python实现地标景点识别的步骤数据收集数据预处理构建卷积神经网络模型模型训练 参考文献 前言
简介 地标景点识别是一种基于计算机视觉技术…

Orange3数据转换(数据采样组件)
组件介绍: 固定数据比例(Fixed proportion of data) 返回整个数据的选定百分比
固定样本量(Fixed sample size) 返回选定数量的数据实例,并可以设置 Sample with replacement(替换样本),该替换样本始终从整个数据集中…
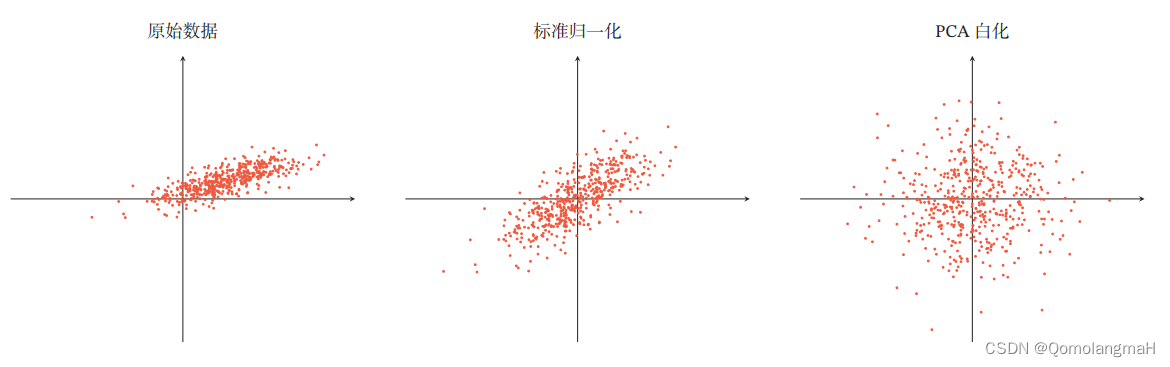
【深度学习实验】网络优化与正则化(五):数据预处理详解——标准化、归一化、白化、去除异常值、处理缺失值
文章目录 一、实验介绍二、实验环境1. 配置虚拟环境2. 库版本介绍 三、优化算法0. 导入必要的库1. 随机梯度下降SGD算法a. PyTorch中的SGD优化器b. 使用SGD优化器的前馈神经网络 2.随机梯度下降的改进方法a. 学习率调整b. 梯度估计修正 3. 梯度估计修正:动量法Momen…

22种transforms数据预处理方法
来源:投稿 作者:阿克西 编辑:学姐 建议搭配视频学习↓
视频链接:https://ai.deepshare.net/detail/p_5df0ad9a09d37_qYqVmt85/6
1.数据增强(data augmentation)
数据增强又称为数据增广,数据…
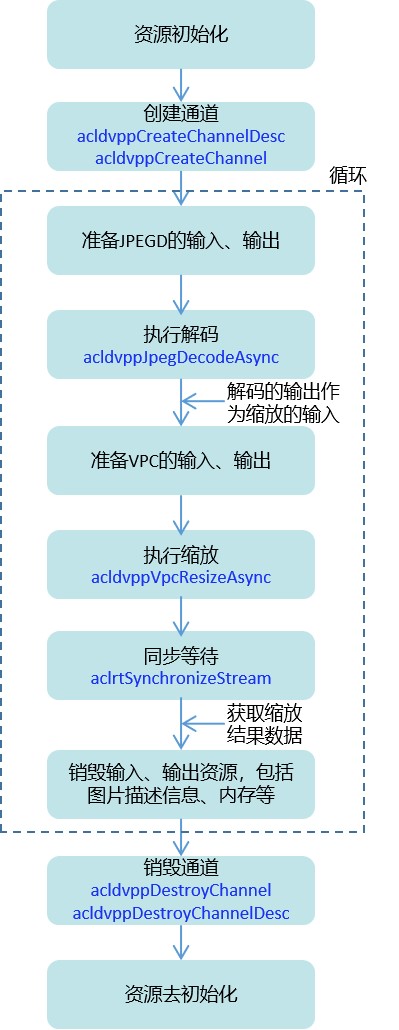
了解AscendCL数据预处理的两种方式:AIPP和DVPP
01 数据预处理的典型使用场景受网络结构和训练方式等因素的影响,绝大多数神经网络模型对输入数据都有格式上的限制。在计算机视觉领域,这个限制大多体现在图像的尺寸、色域、归一化参数等。如果源图或视频的尺寸、格式等与网络模型的要求不一致时&#x…
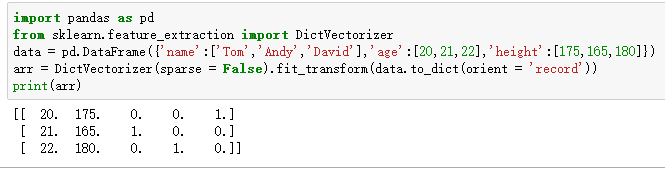
scikit-learn中离散特征二值化
scikit-learn中离散特征二值化 最近在看西瓜书用scikit-learn中的CART去跑西瓜数据集,结果遇到麻烦了,西瓜数据集特征不光离散的,而且还是中文的。。(PS:其实我们的数据集中特征值常常是离散的类别,这个很正…
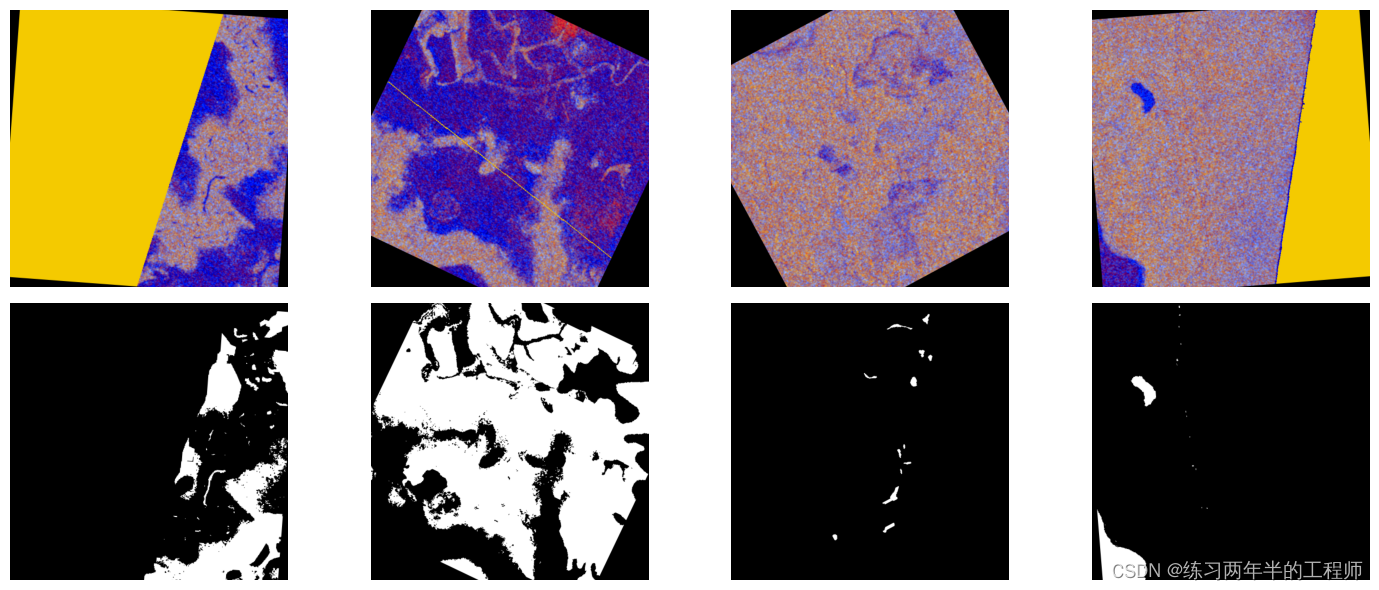
卫星图像应用 - 洪水检测 使用DALI进行数据预处理
这篇文章是上一篇的延申。
运行环境:Google Colab
1. 当今的深度学习应用包含由许多串行运算组成的、复杂的多阶段数据处理流水线,仅依靠 CPU 处理这些流水线已成为限制性能和可扩展性的瓶颈。
2. DALI 是一个用于加载和预处理数据的库,可…
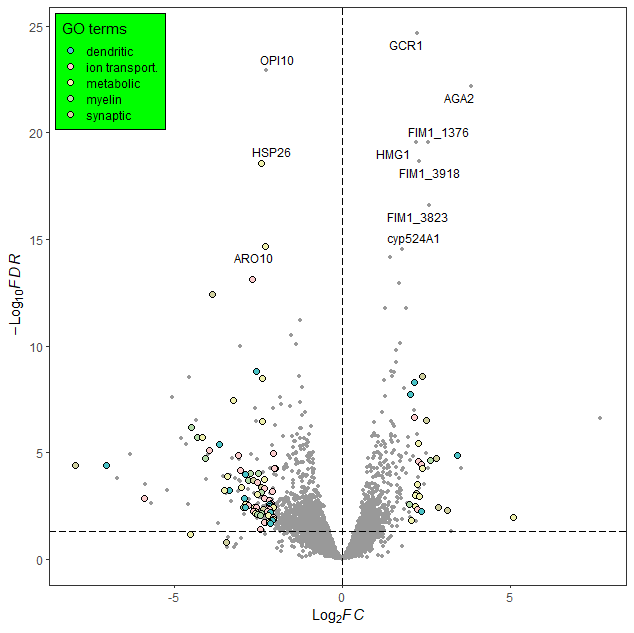
一行代码绘制高分SCI火山图
一、概述
在近半年中,我读了很多的高分SCI文章,很多文章中都有多种不同的火山图,包括「普通的火山图、渐变火山图、以及包含GO通路信息的火山图」!
经过一段时间的文献阅读和资料查询,终于找到了一个好用而且简单的包…
数据预处理之数据标准特征化
Standardization即标准化,尽量将数据转化为均值为零,方差为一的数据,形如标准正态分布(高斯分布)。实际中我们会忽略数据的分布情况,仅仅是通过改变均值来集中数据,然后将非连续特征除以他们的标…

IoT 数据预处理:线性重采样全过程解析
原文:Preprocessing IoT Data: Linear Resampling 作者:neocortex 译者:蒋春华 审校:屠敏 在这篇文章中,我们将描述在分析物联网的时间序列数据的一个最重要的预处理过程:线性重采样。具体而言ÿ…
Orange3数据预处理(转换器组件)
该组件接收数据,然后重新应用之前在模板数据上执行的转换。 这些转换包括选择变量的子集以及从数据中出现的其他变量计算新的变量, 例如,离散化、特征构建、主成分分析(PCA)等。 在Orange3中,描述的这个组件…
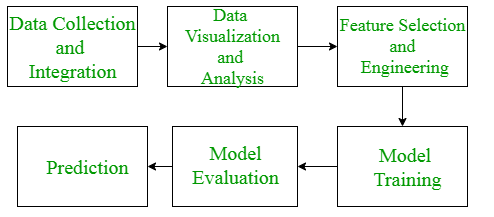
机器学习流程—数据预处理 清洗
机器学习流程—数据预处理 清洗
数据清洗因为它涉及识别和删除任何丢失、重复或不相关的数据。数据清理的目标是确保数据准确、一致且无错误,因为不正确或不一致的数据会对 ML 模型的性能产生负面影响。专业数据科学家通常会在这一步投入大量时间,因为他们相信Better data b…

机器学习中数据预处理——标准化/归一化方法(scaler)
由于工作问题比较忙,有两周没有总结一下工作学习中遇到的问题。
这篇主要是关于机器学习中的数据预处理的scaler变化。
工作中遇到的问题是:流量预测问题,拿到的数据差距非常大,凌晨的通话流量很少几乎为0;但是在早上…